Publications
My publications in reverse chronological order, you can also check my Google Scholar page.
2025
- Flavio Martinelli*, Alexander Van Meegen*, Berfin Simsek, Wulfram Gerstner, and Johanni BreaNeurIPS, 2025
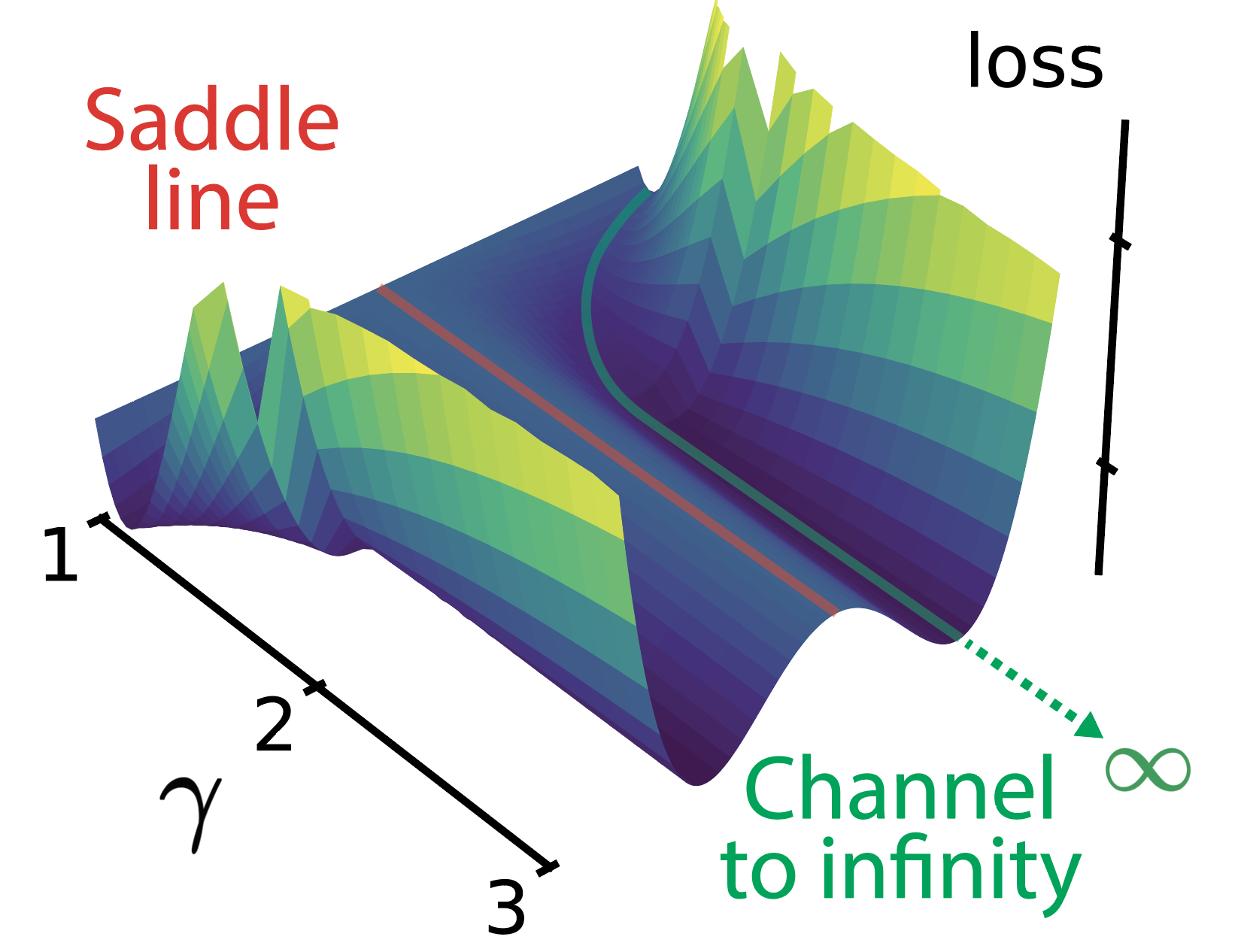
The loss landscapes of neural networks contain minima and saddle points that may be connected in flat regions or appear in isolation. We identify and characterize a special structure in the loss landscape: channels along which the loss decreases extremely slowly, while the output weights of at least two neurons, aᵢ and aⱼ, diverge to ±infinity, and their input weight vectors, 𝘄ᵢ and 𝘄ⱼ, become equal to each other. At convergence, the two neurons implement a gated linear unit: aᵢσ(𝘄ᵢ⋅x) + aⱼσ(𝘄ⱼ⋅x) → σ(𝘄⋅𝘅) + (𝘃⋅𝘅) σ’(𝘄⋅𝘅). Geometrically, these channels to infinity are asymptotically parallel to symmetry-induced lines of critical points. Gradient flow solvers, and related optimization methods like SGD or ADAM, reach the channels with high probability in diverse regression settings, but without careful inspection they look like flat local minima with finite parameter values. Our characterization provides a comprehensive picture of these quasi-flat regions in terms of gradient dynamics, geometry, and functional interpretation. The emergence of gated linear units at the end of the channels highlights a surprising aspect of the computational capabilities of fully connected layers.
@article{martinelli2025flat, title = {Flat Channels to Infinity in Neural Loss Landscapes}, author = {Martinelli, Flavio and Van Meegen, Alexander and Simsek, Berfin and Gerstner, Wulfram and Brea, Johanni}, journal = {NeurIPS}, year = {2025}, doi = {https://doi.org/10.48550/arXiv.2506.14951}, } - Kevin Portner*, Till Zellweger*, Flavio Martinelli, Laura Bégon-Lours, Valeria Bragaglia , and 13 more authors2025
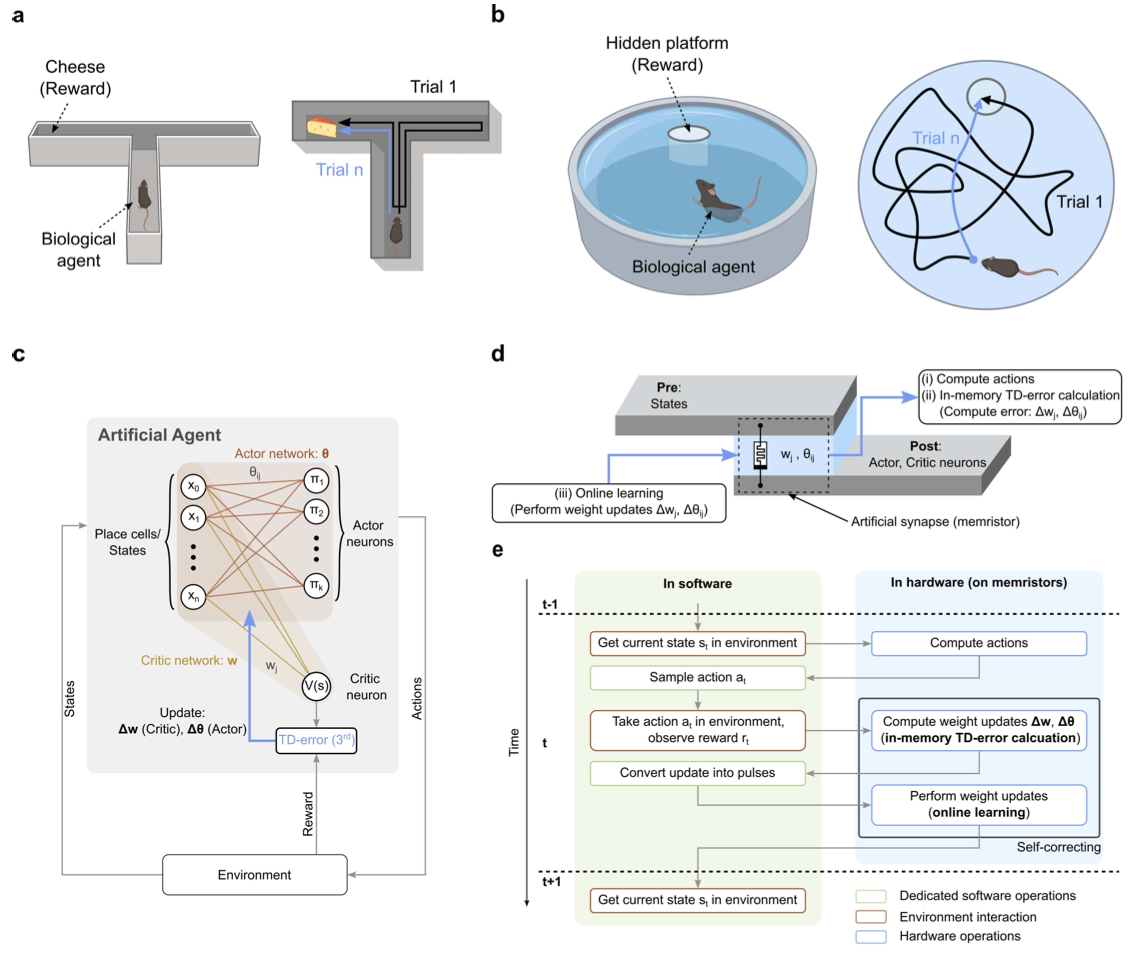
Advancements in memristive devices have given rise to a new generation of specialized hardware for bio-inspired computing. However, the majority of these implementations only draw partial inspiration from the architecture and functionalities of the mammalian brain. Moreover, the use of memristive hardware is typically restricted to specific elements within the learning algorithm, leaving computationally expensive operations to be executed in software. Here, we demonstrate actor-critic temporal difference (TD) learning on analogue memristors, mirroring the principles of reward-based learning in a neural network architecture similar to the one found in biology. Within the learning algorithm, memristors are used as multi-purpose elements: They act as synaptic weights that are trained online, they calculate the weight updates directly in hardware, and they compute the actions for navigating through the environment. Thanks to these features, weight training can take place entirely in-memory, eliminating the need for data movement and enhancing processing speed. Also, our proposed learning scheme possesses self-correction capabilities that effectively counteract noise during the weight update process, which makes it a promising alternative to traditional error mitigation schemes. We test our framework on two classic navigation tasks - the T-maze and the Morris water-maze - using analogue memristors based on the valence change memory (VCM) effect. Our approach represents a first step towards fully in-memory, online, and error-resilient neuromorphic computing engines based on bio-inspired learning schemes.
@article{portner2024actor, title = {Actor-Critic Networks with Analogue Memristors Mimicking Reward-Based Learning}, author = {Portner, Kevin and Zellweger, Till and Martinelli, Flavio and B{\'e}gon-Lours, Laura and Bragaglia, Valeria and Weilenmann, Christoph and Jubin, Daniel and Falcone, Donato and Hermann, Felix and Hrynkevych, Oscar and Stecconi, Tommaso and La Porta, Antonio and Drechsler, Ute and Olziersky, Antonis and Offrein, Bert and Gerstner, Wulfram and Luisier, Mathieu and Emboras, Alexandros}, year = {2025}, doi = {https://doi.org/10.1038/s42256-025-01149-w}, } - Ann Huang, Satpreet H Singh, Flavio Martinelli, and Kanaka RajanNeurIPS, 2025
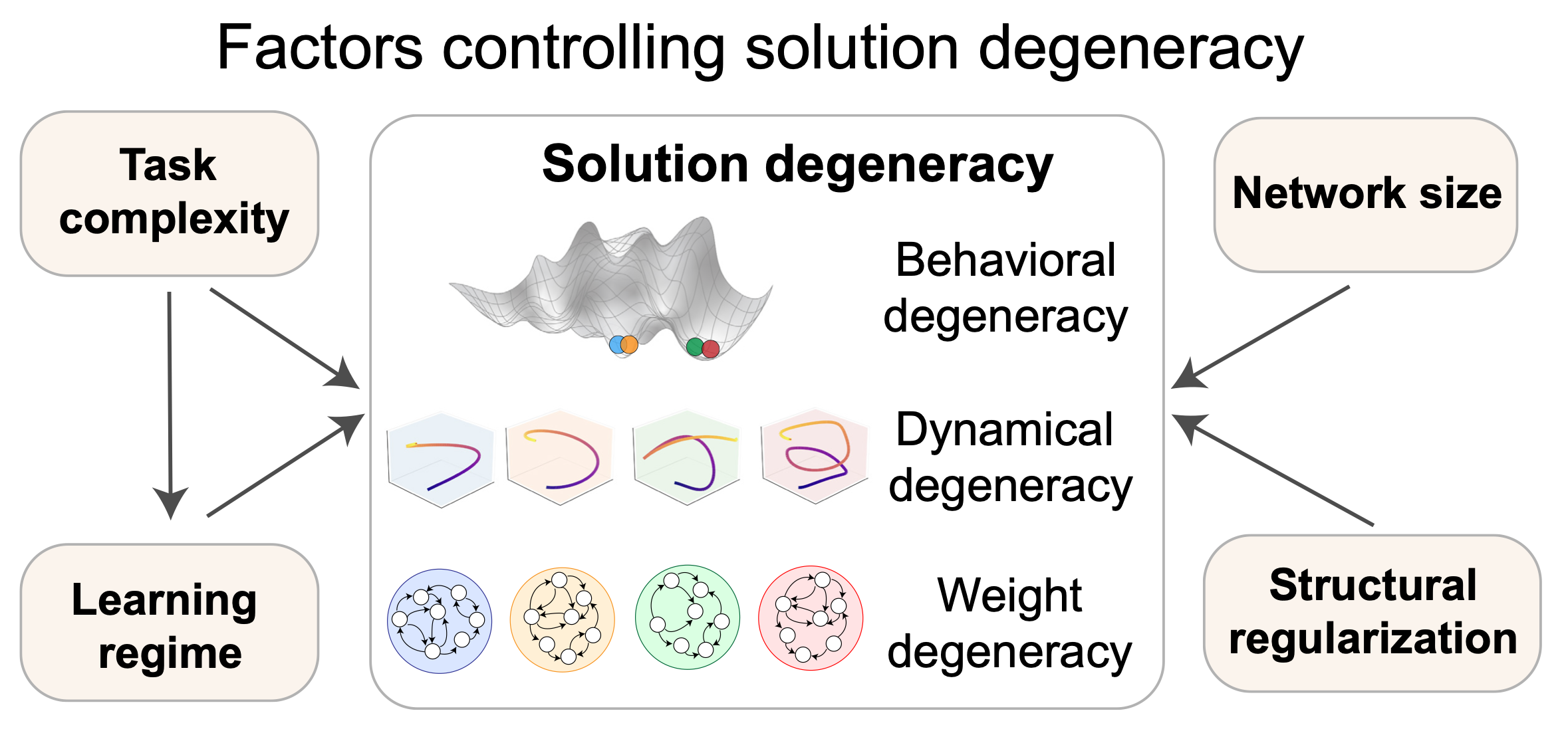
Task-trained recurrent neural networks (RNNs) are widely used in neuroscience and machine learning to model dynamical computations. To gain mechanistic insight into how neural systems solve tasks, prior work often reverse-engineers individual trained networks. However, different RNNs trained on the same task and achieving similar performance can exhibit strikingly different internal solutions-a phenomenon known as solution degeneracy. Here, we develop a unified framework to systematically quantify and control solution degeneracy across three levels: behavior, neural dynamics, and weight space. We apply this framework to 3,400 RNNs trained on four neuroscience-relevant tasks-flip-flop memory, sine wave generation, delayed discrimination, and path integration-while systematically varying task complexity, learning regime, network size, and regularization. We find that higher task complexity and stronger feature learning reduce degeneracy in neural dynamics but increase it in weight space, with mixed effects on behavior. In contrast, larger networks and structural regularization reduce degeneracy at all three levels. These findings empirically validate the Contravariance Principle and provide practical guidance for researchers aiming to tailor RNN solutions-whether to uncover shared neural mechanisms or to model individual variability observed in biological systems. This work provides a principled framework for quantifying and controlling solution degeneracy in task-trained RNNs, offering new tools for building more interpretable and biologically grounded models of neural computation.
@article{huang2025measuring, title = {Measuring and controlling solution degeneracy across task-trained recurrent neural networks}, author = {Huang, Ann and Singh, Satpreet H and Martinelli, Flavio and Rajan, Kanaka}, journal = {NeurIPS}, year = {2025}, doi = {https://doi.org/10.48550/arXiv.2410.03972}, } - Alexander Beiser, Flavio Martinelli, Wulfram Gerstner, and Johanni BreaarXiv preprint arXiv:2511.20312, 2025
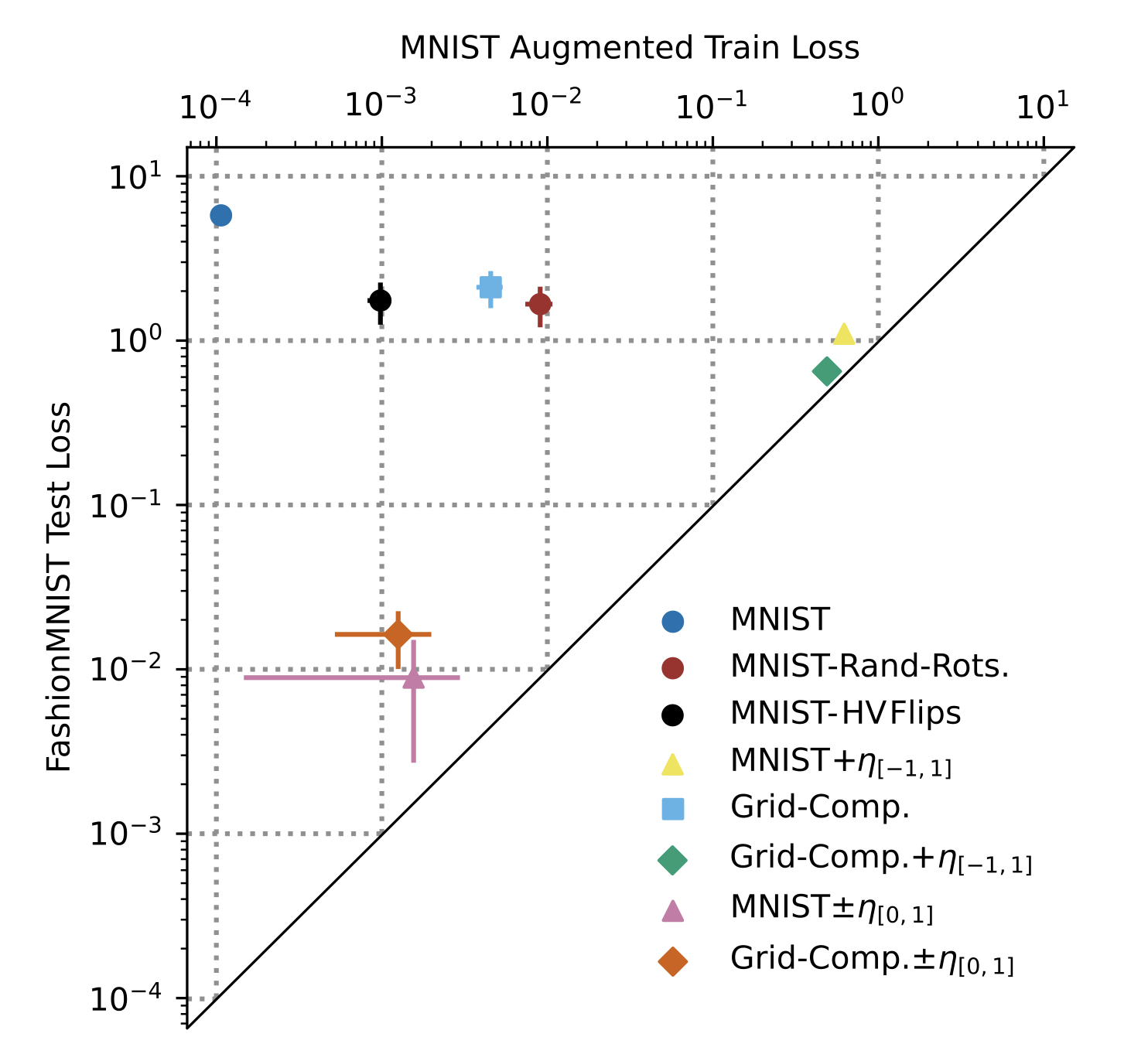
Network weights can be reverse-engineered given enough informative samples of a network’s input-output function. In a teacher-student setup, this translates into collecting a dataset of the teacher mapping – querying the teacher – and fitting a student to imitate such mapping. A sensible choice of queries is the dataset the teacher is trained on. But current methods fail when the teacher parameters are more numerous than the training data, because the student overfits to the queries instead of aligning its parameters to the teacher. In this work, we explore augmentation techniques to best sample the input-output mapping of a teacher network, with the goal of eliciting a rich set of representations from the teacher hidden layers. We discover that standard augmentations such as rotation, flipping, and adding noise, bring little to no improvement to the identification problem. We design new data augmentation techniques tailored to better sample the representational space of the network’s hidden layers. With our augmentations we extend the state-of-the-art range of recoverable network sizes. To test their scalability, we show that we can recover networks of up to 100 times more parameters than training data-points.
@article{beiser2025data, title = {Data Augmentation Techniques to Reverse-Engineer Neural Network Weights from Input-Output Queries}, author = {Beiser, Alexander and Martinelli, Flavio and Gerstner, Wulfram and Brea, Johanni}, journal = {arXiv preprint arXiv:2511.20312}, year = {2025}, doi = {https://arxiv.org/abs/2511.20312}, }
2024
- Flavio Martinelli, Berfin Simsek, Wulfram Gerstner*, and Johanni Brea*In Forty-first International Conference on Machine Learning (ICML) , 2024
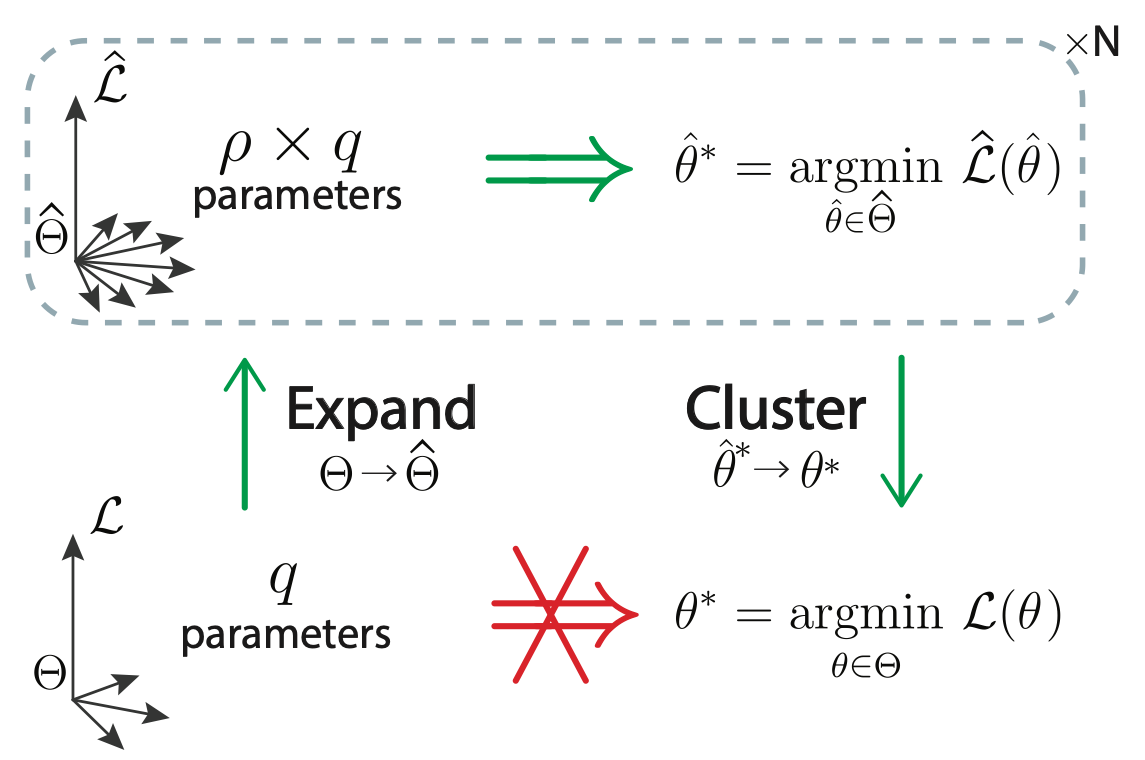
Can we identify the weights of a neural network by probing its input-output mapping? At first glance, this problem seems to have many solutions because of permutation, overparameterisation and activation function symmetries. Yet, we show that the incoming weight vector of each neuron is identifiable up to sign or scaling, depending on the activation function. Our novel method ’Expand-and-Cluster’ can identify layer sizes and weights of a target network for all commonly used activation functions. Expand-and-Cluster consists of two phases: (i) to relax the non-convex optimisation problem, we train multiple overparameterised student networks to best imitate the target function; (ii) to reverse engineer the target network’s weights, we employ an ad-hoc clustering procedure that reveals the learnt weight vectors shared between students – these correspond to the target weight vectors. We demonstrate successful weights and size recovery of trained shallow and deep networks with less than 10% overhead in the layer size and describe an ’ease-of-identifiability’ axis by analysing 150 synthetic problems of variable difficulty.
@inproceedings{martinelli2023expand, title = {Expand-and-Cluster: Parameter Recovery of Neural Networks}, author = {Martinelli, Flavio and Simsek, Berfin and Gerstner, Wulfram and Brea, Johanni}, booktitle = {Forty-first International Conference on Machine Learning (ICML)}, year = {2024}, doi = {}, }
2023
- Johanni Brea, Flavio Martinelli, Berfin Şimşek, and Wulfram GerstnerarXiv preprint arXiv:2301.10638, 2023
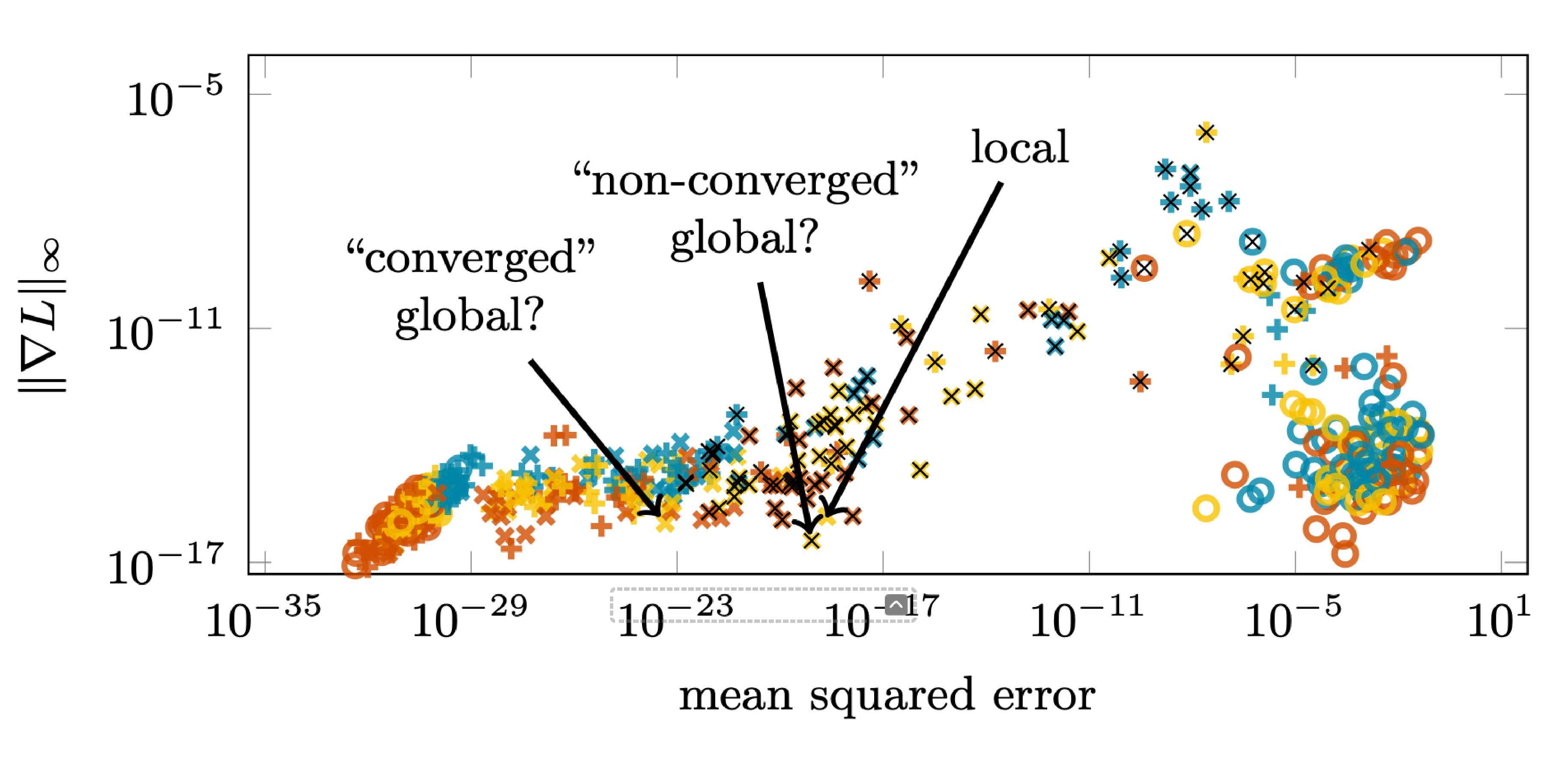
MLPGradientFlow is a software package to solve numerically the gradient flow differential equation θ ̇ = −∇L(θ; D), where θ are the parameters of a multi-layer perceptron, D is some data set, and ∇L is the gradient of a loss function. We show numerically that adaptive first- or higher-order integration methods based on Runge-Kutta schemes have better accuracy and convergence speed than gradient descent with the Adam optimizer. However, we find Newton’s method and approximations like BFGS preferable to find fixed points (local and global minima of L) efficiently and accurately. For small networks and data sets, gradients are usually computed faster than in pytorch and Hessian are computed at least 5× faster. Additionally, the package features an integrator for a teacher-student setup with bias-free, two-layer networks trained with standard Gaussian input in the limit of infinite data. The code is accessible at https://github.com/jbrea/MLPGradientFlow.jl.
@article{brea2023mlpgradientflow, title = {Mlpgradientflow: going with the flow of multilayer perceptrons (and finding minima fast and accurately)}, author = {Brea, Johanni and Martinelli, Flavio and {\c{S}}im{\c{s}}ek, Berfin and Gerstner, Wulfram}, journal = {arXiv preprint arXiv:2301.10638}, year = {2023}, doi = {https://doi.org/10.48550/arXiv.2301.10638}, }
2020
- Flavio Martinelli, Giorgia Dellaferrera, Pablo Mainar, and Milos CernakIn ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2020
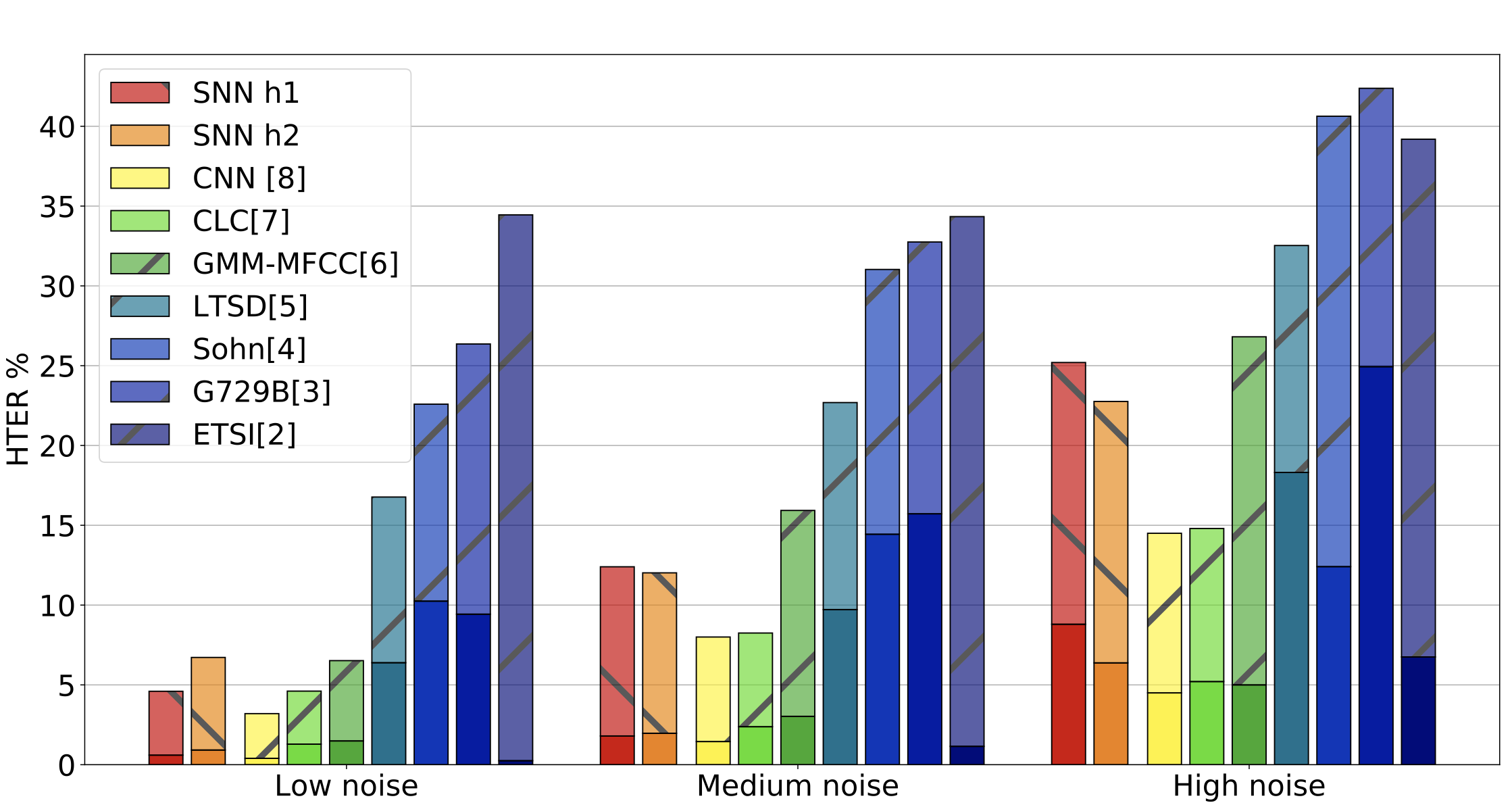
Recent advances in Voice Activity Detection (VAD) are driven by artificial and Recurrent Neural Networks (RNNs), however, using a VAD system in battery-operated devices requires further power efficiency. This can be achieved by neuromorphic hardware, which enables Spiking Neural Networks (SNNs) to perform inference at very low energy consumption. Spiking networks are characterized by their ability to process information efficiently, in a sparse cascade of binary events in time called spikes. However, a big performance gap separates artificial from spiking networks, mostly due to a lack of powerful SNN training algorithms. To overcome this problem we exploit an SNN model that can be recast into a recurrent network and trained with known deep learning techniques. We describe a training procedure that achieves low spiking activity and apply pruning algorithms to remove up to 85% of the network connections with no performance loss. The model competes with state-of-the-art performance at a fraction of the power consumption comparing to other methods.
@inproceedings{martinelli2020spiking, title = {Spiking neural networks trained with backpropagation for low power neuromorphic implementation of voice activity detection}, author = {Martinelli, Flavio and Dellaferrera, Giorgia and Mainar, Pablo and Cernak, Milos}, booktitle = {ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, pages = {8544--8548}, year = {2020}, organization = {IEEE}, doi = {10.1109/ICASSP40776.2020.9053412}, } - Giorgia Dellaferrera, Flavio Martinelli, and Milos CernakIn ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2020
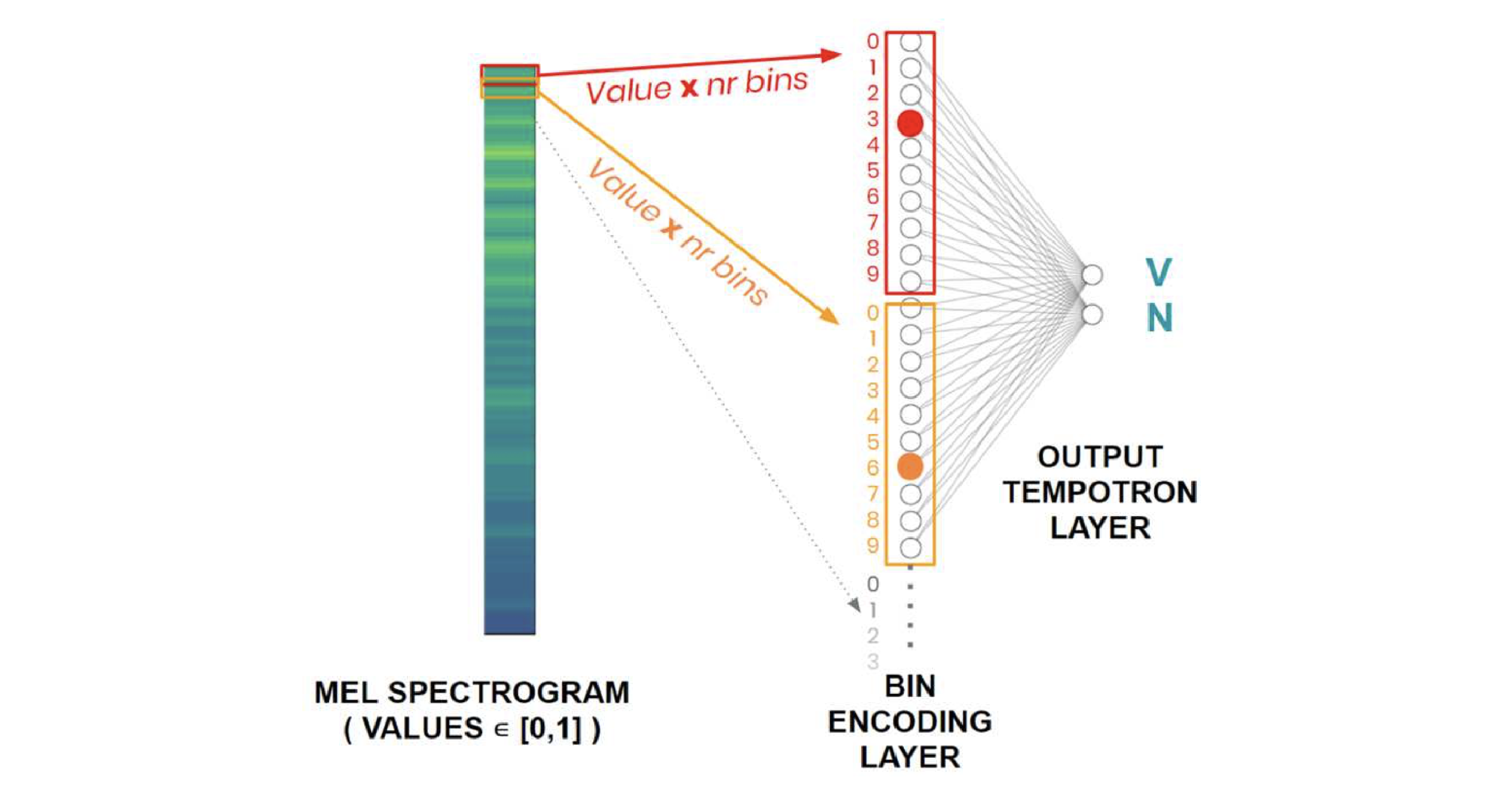
Advances of deep learning for Artificial Neural Networks (ANNs) have led to significant improvements in the performance of digital signal processing systems implemented on digital chips. Although recent progress in low-power chips is remarkable, neuromorphic chips that run Spiking Neural Networks (SNNs) based applications offer an even lower power consumption, as a consequence of the ensuing sparse spikebased coding scheme. In this work, we develop a SNN-based Voice Activity Detection (VAD) system that belongs to the building blocks of any audio and speech processing system. We propose to use the bin encoding, a novel method to convert log mel filterbank bins of single-time frames into spike patterns. We integrate the proposed scheme in a bilayer spiking architecture which was evaluated on the QUT-NOISE-TIMIT corpus. Our approach shows that SNNs enable an ultra low-0power implementation of a VAD classifier that consumes only 3.8 μW, while achieving state-of-the-art performance.
@inproceedings{dellaferrera2020bin, title = {A bin encoding training of a spiking neural network based voice activity detection}, author = {Dellaferrera, Giorgia and Martinelli, Flavio and Cernak, Milos}, booktitle = {ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, pages = {3207--3211}, year = {2020}, organization = {IEEE}, doi = {10.1109/ICASSP40776.2020.9054761}, }